 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOPOS: High-Fidelity and Efficient Industry-Grade 3D Head Generation
May 14, 2026High-fidelity 3D head generation plays a crucial role in the film, animation and video game industries. In industrial pipelines, studios typically enforce a fixed reference topology across all head assets, as such a clean and uniform topology is a prerequisite for production-level rigging, skinning and animation. In this paper, we present TOPOS, a framework tailored for single image conditioned 3D head generation that jointly recovers geometry and appearance under such an industry-standard topology. In contrast to general 3D generative models which produce triangle meshes with inconsistent topology and numerous vertices, hindering semantic correspondence and asset-level reuse, TOPOS generates head meshes with a fixed, studio-style topology, enabling consistent vertex-level correspondence across all generated heads. To model heads under this unified topology, we proposed a novel variational autoencoder structure, termed TOPOS-VAE. Inspired by multi-model large language models (MLLMs), our TOPOS-VAE leverages the Perceiver Resampler to convert input pointclouds sampled from head meshes of diverse topologies into the target reference topology. Building upon TOPOS-VAE's structured latent space, we train a rectified flow transformer, TOPOS-DiT, to efficiently generate high-fidelity head meshes from a single image. We further present TOPOS-Texture, an end-to-end module that produces relightable UV texture maps from the same portrait image via fine-tuning a multimodal image generative model. The generated textures are spatially aligned with the underlying mesh geometry and faithfully preserve high-frequency appearance details. Extensive experiments demonstrate that TOPOS achieves state-of-the-art performance on 3D head generation, surpassing both classical face reconstruction methods and general 3D object generative models, highlighting its effectiveness for digital human creation.
High-Fidelity Single-Image Head Modeling with Industry-Grade Topology
May 06, 2026We present a single-image head mesh reconstruction framework that addresses the longstanding challenge of simultaneously preserving facial identity and producing industry-grade topology. Our framework adopts a coarse-to-fine optimization pipeline that refines a rigged template across three stages -- rig, joint, and vertex -- achieving stable convergence and consistent topology. To mitigate the ill-posed nature of single-image 3D face reconstruction and ensure identity preservation, we employ a normal consistency objective jointly with landmark alignment. To further preserve local surface structure and enforce topological regularity, we introduce geometry-aware constraints based on Gaussian curvature and conformal consistency, along with auxiliary regularizations that correct fine artifacts such as lip seams and eyelid discontinuities. Our hierarchical optimization with geometry-aware regularization yields meshes with semantically meaningful edge flow and industry-grade topology. After geometry reconstruction, we extract UV-space texture and normal maps to preserve appearance details for visualization and downstream use. In a user study with 22 professional technical artists, our results were assessed as approaching industry-grade usability, and 95% of participants ranked our method as the top-performing approach, underscoring its effectiveness for real-world digital human production.
PerformRecast: Expression and Head Pose Disentanglement for Portrait Video Editing
Mar 20, 2026This paper primarily investigates the task of expression-only portrait video performance editing based on a driving video, which plays a crucial role in animation and film industries. Most existing research mainly focuses on portrait animation, which aims to animate a static portrait image according to the facial motion from the driving video. As a consequence, it remains challenging for them to disentangle the facial expression from head pose rotation and thus lack the ability to edit facial expression independently. In this paper, we propose PerformRecast, a versatile expression-only video editing method which is dedicated to recast the performance in existing film and animation. The key insight of our method comes from the characteristics of 3D Morphable Face Model (3DMM), which models the face identity, facial expression and head pose of 3D face mesh with separate parameters. Therefore, we improve the keypoints transformation formula in previous methods to make it more consistent with 3DMM model, which achieves a better disentanglement and provides users with much more fine-grained control. Furthermore, to avoid the misalignment around the boundary of face in generated results, we decouple the facial and non-facial regions of input portrait images and pre-train a teacher model to provide separate supervision for them. Extensive experiments show that our method produces high-quality results which are more faithful to the driving video, outperforming existing methods in both controllability and efficiency. Our code, data and trained models are available at https://youku-aigc.github.io/PerformRecast.
Skeleton2Stage: Reward-Guided Fine-Tuning for Physically Plausible Dance Generation
Feb 14, 2026Despite advances in dance generation, most methods are trained in the skeletal domain and ignore mesh-level physical constraints. As a result, motions that look plausible as joint trajectories often exhibit body self-penetration and Foot-Ground Contact (FGC) anomalies when visualized with a human body mesh, reducing the aesthetic appeal of generated dances and limiting their real-world applications. We address this skeleton-to-mesh gap by deriving physics-based rewards from the body mesh and applying Reinforcement Learning Fine-Tuning (RLFT) to steer the diffusion model toward physically plausible motion synthesis under mesh visualization. Our reward design combines (i) an imitation reward that measures a motion's general plausibility by its imitability in a physical simulator (penalizing penetration and foot skating), and (ii) a Foot-Ground Deviation (FGD) reward with test-time FGD guidance to better capture the dynamic foot-ground interaction in dance. However, we find that the physics-based rewards tend to push the model to generate freezing motions for fewer physical anomalies and better imitability. To mitigate it, we propose an anti-freezing reward to preserve motion dynamics while maintaining physical plausibility. Experiments on multiple dance datasets consistently demonstrate that our method can significantly improve the physical plausibility of generated motions, yielding more realistic and aesthetically pleasing dances. The project page is available at: https://jjd1123.github.io/Skeleton2Stage/
FreeInv: Free Lunch for Improving DDIM Inversion
Mar 29, 2025



Naive DDIM inversion process usually suffers from a trajectory deviation issue, i.e., the latent trajectory during reconstruction deviates from the one during inversion. To alleviate this issue, previous methods either learn to mitigate the deviation or design cumbersome compensation strategy to reduce the mismatch error, exhibiting substantial time and computation cost. In this work, we present a nearly free-lunch method (named FreeInv) to address the issue more effectively and efficiently. In FreeInv, we randomly transform the latent representation and keep the transformation the same between the corresponding inversion and reconstruction time-step. It is motivated from a statistical perspective that an ensemble of DDIM inversion processes for multiple trajectories yields a smaller trajectory mismatch error on expectation. Moreover, through theoretical analysis and empirical study, we show that FreeInv performs an efficient ensemble of multiple trajectories. FreeInv can be freely integrated into existing inversion-based image and video editing techniques. Especially for inverting video sequences, it brings more significant fidelity and efficiency improvements. Comprehensive quantitative and qualitative evaluation on PIE benchmark and DAVIS dataset shows that FreeInv remarkably outperforms conventional DDIM inversion, and is competitive among previous state-of-the-art inversion methods, with superior computation efficiency.
Uncertainty Quantification in Stereo Matching
Dec 24, 2024



Stereo matching plays a crucial role in various applications, where understanding uncertainty can enhance both safety and reliability. Despite this, the estimation and analysis of uncertainty in stereo matching have been largely overlooked. Previous works often provide limited interpretations of uncertainty and struggle to separate it effectively into data (aleatoric) and model (epistemic) components. This disentanglement is essential, as it allows for a clearer understanding of the underlying sources of error, enhancing both prediction confidence and decision-making processes. In this paper, we propose a new framework for stereo matching and its uncertainty quantification. We adopt Bayes risk as a measure of uncertainty and estimate data and model uncertainty separately. Experiments are conducted on four stereo benchmarks, and the results demonstrate that our method can estimate uncertainty accurately and efficiently. Furthermore, we apply our uncertainty method to improve prediction accuracy by selecting data points with small uncertainties, which reflects the accuracy of our estimated uncertainty. The codes are publicly available at https://github.com/RussRobin/Uncertainty.
Multiscale Representation for Real-Time Anti-Aliasing Neural Rendering
Apr 20, 2023



The rendering scheme in neural radiance field (NeRF) is effective in rendering a pixel by casting a ray into the scene. However, NeRF yields blurred rendering results when the training images are captured at non-uniform scales, and produces aliasing artifacts if the test images are taken in distant views. To address this issue, Mip-NeRF proposes a multiscale representation as a conical frustum to encode scale information. Nevertheless, this approach is only suitable for offline rendering since it relies on integrated positional encoding (IPE) to query a multilayer perceptron (MLP). To overcome this limitation, we propose mip voxel grids (Mip-VoG), an explicit multiscale representation with a deferred architecture for real-time anti-aliasing rendering. Our approach includes a density Mip-VoG for scene geometry and a feature Mip-VoG with a small MLP for view-dependent color. Mip-VoG encodes scene scale using the level of detail (LOD) derived from ray differentials and uses quadrilinear interpolation to map a queried 3D location to its features and density from two neighboring downsampled voxel grids. To our knowledge, our approach is the first to offer multiscale training and real-time anti-aliasing rendering simultaneously. We conducted experiments on multiscale datasets, and the results show that our approach outperforms state-of-the-art real-time rendering baselines.
NeuDA: Neural Deformable Anchor for High-Fidelity Implicit Surface Reconstruction
Mar 04, 2023



This paper studies implicit surface reconstruction leveraging differentiable ray casting. Previous works such as IDR and NeuS overlook the spatial context in 3D space when predicting and rendering the surface, thereby may fail to capture sharp local topologies such as small holes and structures. To mitigate the limitation, we propose a flexible neural implicit representation leveraging hierarchical voxel grids, namely Neural Deformable Anchor (NeuDA), for high-fidelity surface reconstruction. NeuDA maintains the hierarchical anchor grids where each vertex stores a 3D position (or anchor) instead of the direct embedding (or feature). We optimize the anchor grids such that different local geometry structures can be adaptively encoded. Besides, we dig into the frequency encoding strategies and introduce a simple hierarchical positional encoding method for the hierarchical anchor structure to flexibly exploit the properties of high-frequency and low-frequency geometry and appearance. Experiments on both the DTU and BlendedMVS datasets demonstrate that NeuDA can produce promising mesh surfaces.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Dec 04, 2022



This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
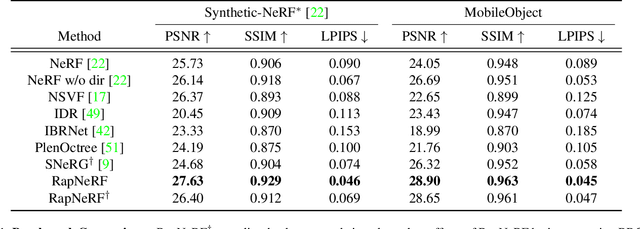
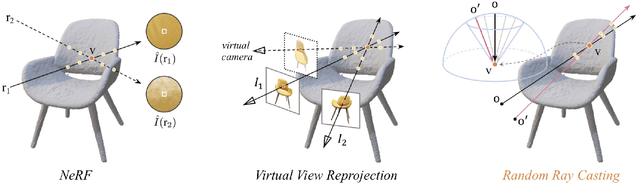
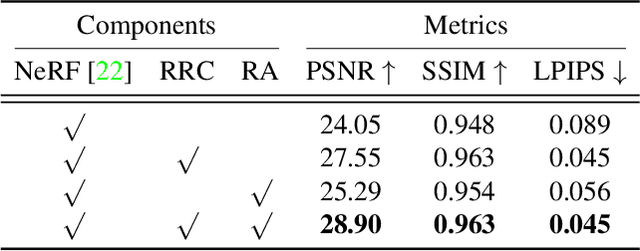
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.